Replicate
About Replicate
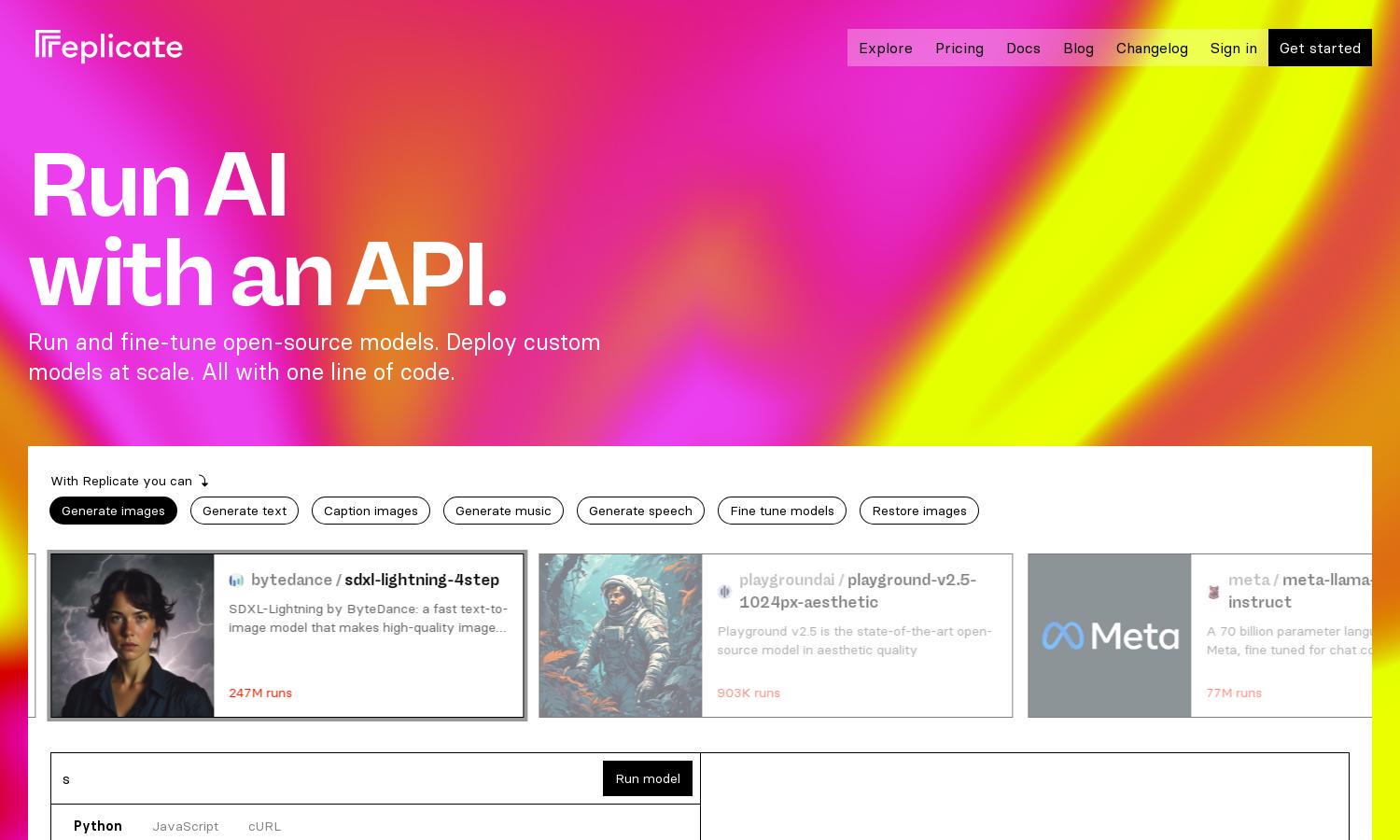
Replicate is a cloud-based platform designed for developers and businesses to run and fine-tune open-source AI models effortlessly. Users can deploy custom models and make the most of innovative AI features with just a line of code. Replicate unlocks the true potential of AI for any project.
Replicate offers flexible pricing based on usage, including CPU and various GPU options, starting at $0.000100/sec. Users can benefit from automatic scaling, ensuring they only pay for active compute time. Upgrading to advanced tiers enhances performance for heavier workloads while maintaining cost efficiency.
Replicate boasts a clean, user-friendly interface that streamlines the model deployment process. With intuitive navigation and a well-organized layout, users can easily access and manage their AI models, ensuring a smooth experience. The design focuses on simplicity and efficiency for all users, from beginners to experts.
How Replicate works
Users start by signing up for Replicate and gaining access to a library of open-source models. After selecting a model, they can run it with straightforward code syntax or fine-tune it with their own data. The platform's API enables seamless integration, allowing developers to deploy applications rapidly and efficiently.
Key Features for Replicate
One-line model deployment
Replicate’s unique one-line model deployment feature allows users to run complex AI models instantly, enhancing productivity. This means developers can focus on building applications without worrying about infrastructural complexities, making Replicate a vital tool for any AI-driven project.
Fine-tuning AI models
Replicate enables users to fine-tune AI models with their own datasets, enhancing performance traits specific to their needs. This feature allows developers to create customized AI solutions tailored to individual objectives, making Replicate a versatile platform for innovative projects.
Automatic scaling
Replicate automatically scales resources based on traffic, ensuring that applications run smoothly under varying loads. This feature not only optimizes resource usage but also significantly reduces operational costs, providing users with an efficient and economical solution for deploying AI capabilities.
You may also like: