Friendli Engine
About Friendli Engine
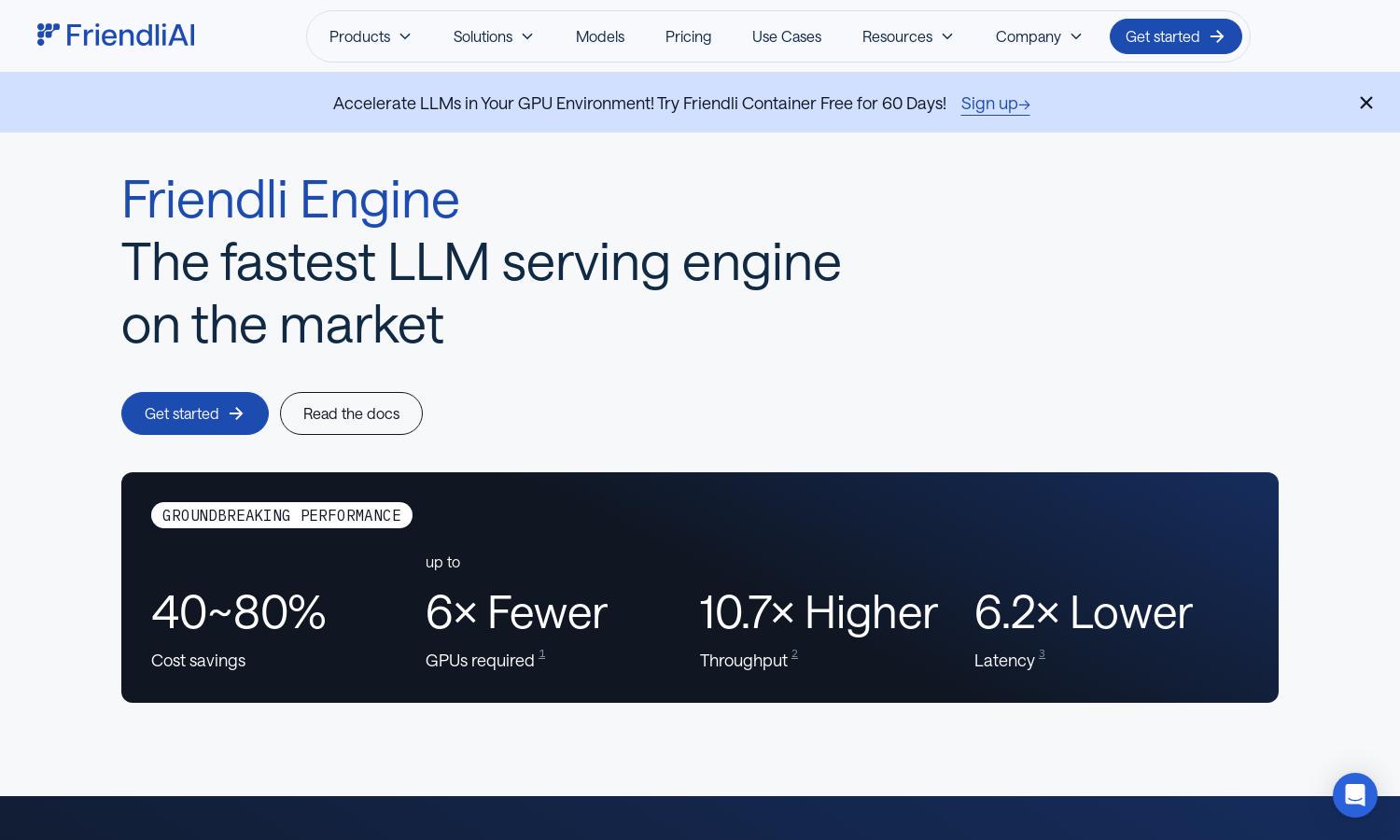
Friendli Engine is designed for deploying and fine-tuning LLMs efficiently, leveraging H100 GPUs for optimal performance. Its innovative Iteration Batching technology handles simultaneous requests significantly faster, making it an excellent choice for businesses seeking cost-effective generative AI solutions without sacrificing quality.
Friendli Engine offers flexible pricing tiers that cater to different needs, from basic access to premium features. Each tier includes significant cost savings for extensive LLM serving, making it a valuable investment for users seeking to optimize their generative AI operations while ensuring high throughput.
Friendli Engine features a user-centric interface designed to streamline interactions with its advanced LLM serving capabilities. The layout intuitively guides users through deploying models and accessing key features, ensuring a seamless experience that enhances productivity in generative AI applications.
How Friendli Engine works
Users start by signing up on Friendli Engine and selecting a pricing plan. Once onboarded, they can easily navigate through its dashboard to deploy generative AI models using the Friendli Engine. Users benefit from advanced functionalities like Iteration Batching and TCache, enabling swift processing of concurrent requests while maintaining cost efficiency.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine’s Iteration Batching technology revolutionizes LLM inference by allowing concurrent generation requests with minimized latency. This feature dramatically enhances throughput, making it a standout solution in the market. Users can enjoy unparalleled performance while optimizing resources on platforms like Friendli Engine.
Multi-LoRA Serving Capability
The Multi-LoRA serving capability allows Friendli Engine to efficiently utilize multiple LoRA models on fewer GPUs, promoting resource savings and making LLM customization more accessible. This unique feature delivers enhanced performance and flexibility, aligning perfectly with the needs of users integrating various models.
Friendli TCache Optimization
Friendli TCache intelligently caches frequently used computations, drastically reducing GPU workload and enhancing Time to First Token (TTFT). This optimization feature makes Friendli Engine exceptionally faster than competing solutions, providing users efficient deployment and an overall improved user experience in generative AI functions.
You may also like: