diffray vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
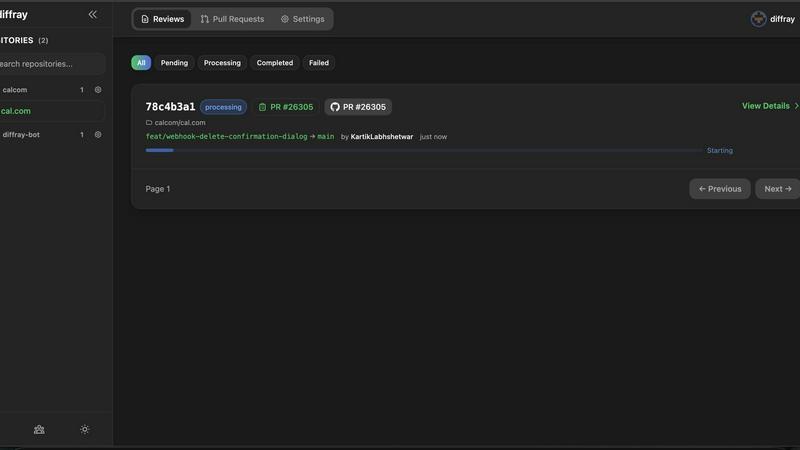
diffray
Diffray's AI agents catch real bugs in code reviews to boost software quality.
Last updated: February 28, 2026
OpenMark AI benchmarks over 100 LLMs on your specific task to find the best model for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
diffray
OpenMark AI

Feature Comparison
diffray
Multi-Agent Specialized Architecture
At the core of diffray is its revolutionary multi-agent system, featuring over 30 AI agents, each trained for a specific review discipline. Instead of one model trying to do everything, you have a dedicated security agent scanning for vulnerabilities like SQL injection, a performance agent identifying inefficient loops or memory leaks, a bug-detection agent catching logical errors, and many more. This specialization ensures deep, contextual analysis that generic tools miss, leading to far more relevant and accurate feedback on every pull request.
Drastically Reduced False Positives
One of the biggest frustrations with automated code review is noise—irrelevant or incorrect suggestions that developers must sift through. diffray's targeted agent system is precision-engineered to minimize this noise. By applying domain-specific rules and context-aware analysis, it filters out irrelevant alerts. This results in an approximately 87% reduction in false positives compared to conventional tools, ensuring that developers can trust the feedback they receive and focus their energy on fixing genuine issues.
Comprehensive Issue Detection
While reducing noise, diffray simultaneously increases signal strength. Its ensemble of specialized agents works in concert to examine code from every critical angle. This comprehensive scrutiny leads to a threefold increase in the detection of real, substantive issues—from subtle security flaws and performance bottlenecks to deviations from best practices and potential bugs that would otherwise reach production. It acts like an entire expert review panel automated into your workflow.
Seamless CI/CD Integration
diffray is built for the modern developer workflow and integrates directly into the tools teams already use. It connects natively with GitHub and GitLab, posting detailed, agent-categorized comments directly onto pull requests. This seamless integration requires no change in developer habit; reviews happen automatically on every PR, providing instant, actionable insights within the existing development environment and continuous integration/continuous delivery (CI/CD) pipeline.
OpenMark AI
Plain Language Task Description
You don't need to be a prompt engineering expert to start benchmarking. OpenMark AI allows you to describe the task you want to test in simple, natural language. The platform then configures the benchmark based on your description, making advanced LLM evaluation accessible to developers, product managers, and teams without deep technical expertise in model fine-tuning or complex setup procedures.
Multi-Model Comparison in One Session
Instead of manually testing models one by one across different platforms, OpenMark AI lets you run your identical prompt against dozens of models simultaneously. This side-by-side testing environment provides an immediate, apples-to-apples comparison, saving hours of manual work and providing clear, actionable insights into which model performs best for your specific use case.
Real Cost & Performance Metrics
The platform goes beyond simple accuracy scores. It executes real API calls to each model and reports back the actual cost per request, latency, and a scored quality metric based on your task. This gives you a complete picture of the trade-offs between speed, expense, and effectiveness, allowing for true cost-efficiency calculations before you commit to an API.
Stability and Variance Analysis
A single, lucky output from a model is misleading. OpenMark AI runs your task multiple times for each model to measure consistency. The results show variance across these repeat runs, highlighting which models produce stable, reliable outputs and which ones are unpredictable. This is crucial for deploying production features that users can depend on.
Use Cases
diffray
Accelerating Enterprise Development Cycles
Large development teams working on complex applications face immense pressure to release features quickly without compromising quality. Manual reviews become a major bottleneck. diffray integrates into their enterprise GitHub/GitLab setup, providing instant, expert-level preliminary reviews on every PR. This slashes the initial review time, allowing senior engineers to focus on architectural feedback rather than hunting for basic bugs, thereby accelerating overall development velocity and maintaining high code standards at scale.
Enhancing Security Posture for Startups
Startups and small teams often lack dedicated security expertise, making their code vulnerable to attacks. diffray acts as an always-available security expert. Its specialized security agent automatically scans every pull request for common and advanced vulnerabilities (e.g., XSS, insecure dependencies, hard-coded secrets). This proactive catch prevents security debt from accumulating and helps startups build securely from the ground up, which is crucial for trust and compliance.
Maintaining Code Quality in Fast-Growing Teams
As teams scale and onboard new developers, maintaining consistent code quality and adherence to best practices becomes challenging. diffray enforces code standards automatically. Its best-practice and style-guide agents review every PR for consistency, readability, and adherence to team conventions, acting as a tireless mentor for new hires and a consistency check for everyone. This ensures the codebase remains clean, maintainable, and scalable as the team grows.
Reducing Bug Escape to Production
Even with thorough testing, subtle logical bugs and edge cases can escape into production, causing outages and user dissatisfaction. diffray’s bug-detection and logic-analysis agents scrutinize code changes for these hard-to-find issues—like race conditions, null pointer exceptions, or incorrect boundary conditions. By catching them at the PR stage, it significantly reduces bug escape rates, leading to more stable releases and less firefighting for the engineering team.
OpenMark AI
Pre-Deployment Model Selection
Before integrating an LLM into a new chatbot, content generation feature, or data processing pipeline, teams can use OpenMark AI to validate which model from the vast available catalog best fits their workflow. This ensures the chosen model aligns with required quality, cost constraints, and performance benchmarks, reducing the risk of post-launch failures or budget overruns.
Cost Optimization for Existing Features
For teams already using an LLM API, OpenMark AI serves as a tool for periodic cost-performance reviews. By benchmarking their current task against newer or alternative models, they can identify if a different provider offers comparable quality at a lower cost or better performance for the same budget, leading to significant long-term savings.
Evaluating Model Consistency for Critical Tasks
When building applications where output reliability is non-negotiable—such as legal document analysis, medical information extraction, or financial summarization—testing for consistency is key. OpenMark AI's variance analysis helps teams disqualify models with high output fluctuation and select those that deliver dependable results every time.
Prototyping and Research for AI Products
Researchers and product innovators exploring new AI capabilities can use OpenMark AI to rapidly prototype ideas. By quickly testing how different models handle a novel task like complex agent routing or multimodal analysis, they can gather data on feasibility and performance without investing in extensive infrastructure or API integrations upfront.
Overview
About diffray
In the fast-paced world of software development, code reviews are a critical bottleneck. Teams struggle with lengthy review cycles, generic feedback that misses critical issues, and an overwhelming number of false positives that waste developer time and erode trust in automated tools. This inefficiency slows down releases and risks letting bugs, security flaws, and performance issues slip into production. diffray is engineered to solve this exact problem. It is an advanced, AI-powered code review assistant that transforms pull request (PR) analysis from a tedious, error-prone task into a swift, precise, and deeply insightful process. Unlike tools that use a single, generalized AI model, diffray employs a sophisticated multi-agent architecture with over 30 specialized AI agents. Each agent is an expert in a specific domain—such as security vulnerabilities, performance anti-patterns, common bugs, language-specific best practices, and even SEO for web code. This targeted approach allows diffray to conduct a contextual, multi-faceted analysis of every code change, dramatically improving accuracy. The result is a proven 87% reduction in false positives and a 3x increase in detecting real, actionable issues. Designed for development teams of all sizes, diffray integrates seamlessly into existing GitHub and GitLab workflows, empowering teams to ship higher-quality code faster by cutting average weekly PR review time from 45 minutes to just 12 minutes per developer.
About OpenMark AI
Choosing the right large language model (LLM) for your AI feature is a high-stakes gamble. Relying on marketing benchmarks or testing one model at a time leaves you guessing about real-world performance, true cost, and output consistency. This uncertainty leads to shipping features that are either too expensive, unreliable, or underperform. OpenMark AI solves this critical pre-deployment challenge. It is a hosted web application designed for developers and product teams to perform task-level LLM benchmarking. You simply describe your specific task in plain language—be it data extraction, translation, or agent routing—and run the same prompts against a vast catalog of over 100 models in a single session. The platform provides side-by-side comparisons using real API calls, not cached data, measuring scored quality, cost per request, latency, and critically, stability across repeat runs to show variance. This means you see which model consistently delivers quality for your unique need at a sustainable cost, eliminating guesswork. With a hosted credit system, you bypass the hassle of configuring multiple API keys, making professional-grade benchmarking accessible without setup. OpenMark AI is built for those who care about cost efficiency (quality relative to price) and consistency, ensuring you deploy with confidence.
Frequently Asked Questions
diffray FAQ
How does diffray's multi-agent system differ from a single AI model?
A single AI model is a generalist; it has broad knowledge but lacks deep expertise in any specific area, often leading to generic or incorrect suggestions. diffray's multi-agent system is like having a team of specialists. Each of the 30+ agents is finely tuned for a specific domain (security, performance, etc.). They work together to provide a layered, context-rich analysis that is far more accurate and comprehensive, which is why we see drastically fewer false positives and many more real issues found.
What platforms and version control systems does diffray integrate with?
diffray is designed for seamless integration into modern development workflows. It currently offers direct, native integrations with GitHub and GitLab, the two most popular version control and collaboration platforms. Once installed, it automatically analyzes pull requests and merge requests, posting comments directly in the interface developers use every day, with no need for context-switching to a separate dashboard.
How does diffray achieve an 87% reduction in false positives?
This reduction is a direct result of our specialized agent architecture. Each agent uses domain-specific rules, patterns, and contextual understanding to evaluate code. For example, the security agent knows the difference between a real vulnerability and a benign code pattern that looks similar. This precision allows agents to filter out the "noise" that generic tools flag, ensuring that the vast majority of alerts raised are legitimate and actionable for the developer.
Is diffray suitable for small development teams or solo developers?
Absolutely. While diffray delivers tremendous value at scale for large teams, it is equally powerful for small teams and solo developers. It acts as an always-available peer reviewer, catching issues that a single pair of eyes might miss. For small teams, it enforces quality and security standards from the start, preventing technical debt and helping them build robust products efficiently without the need for a large, senior-led review process.
OpenMark AI FAQ
How does OpenMark AI differ from standard model leaderboards?
Standard leaderboards often use generic, one-size-fits-all benchmarks (like MMLU or HellaSwag) that may not reflect your specific task. They also typically show "best-case" or cached results. OpenMark AI requires you to describe your actual task, runs fresh API calls against models in real-time, and measures metrics critical for deployment: your task's quality score, actual API cost, latency, and consistency across multiple runs.
Do I need my own API keys to use OpenMark AI?
No, one of the core conveniences of OpenMark AI is that it operates on a hosted credit system. You purchase credits through OpenMark and the platform manages the API calls to providers like OpenAI, Anthropic, and Google on your behalf. This eliminates the need to sign up for, configure, and manage multiple API keys just to run a comparison.
What kind of tasks can I benchmark with OpenMark AI?
You can benchmark virtually any task you would use an LLM for. The platform is designed for task-level evaluation, including but not limited to text classification, translation, data extraction from documents, question answering, content generation, code explanation, sentiment analysis, and testing components of Retrieval-Augmented Generation (RAG) or agentic workflows.
How does OpenMark AI measure the "quality" of a model's output?
Quality scoring is based on the specific task you define. The platform uses automated evaluation methods tailored to your benchmark's goal. This could involve checking for correctness against a defined answer, using a more powerful LLM as a judge to grade responses, or employing other metrics like semantic similarity. The method is configured to align with your success criteria.
Alternatives
diffray Alternatives
diffray is an AI-powered code review tool in the development category, designed to streamline the pull request process. It uses a multi-agent system to catch real bugs and enforce best practices with minimal false positives, aiming to significantly cut down review time and improve code quality. Users often explore alternatives for various reasons. These can include budget constraints, the need for integration with specific platforms or CI/CD pipelines, or a requirement for different feature sets like support for particular programming languages or frameworks. The search for the right tool is highly individual to a team's workflow and technical stack. When evaluating alternatives, key considerations should be the accuracy of feedback and the reduction of noise, the tool's understanding of your codebase context, and the overall impact on developer velocity. The goal is to find a solution that integrates seamlessly, provides actionable insights, and ultimately makes the review process more efficient without sacrificing depth.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It helps teams compare cost, speed, quality, and stability across 100+ LLMs using real API calls, all from a single browser-based interface without needing individual provider keys. Users often explore alternatives for various reasons, such as needing a different pricing model, requiring deeper technical integrations like a dedicated API or SDK, or seeking tools focused on different stages of the AI lifecycle, like ongoing monitoring rather than pre-deployment validation. When evaluating other options, consider your core need: do you require hosted simplicity or self-hosted control? Are you benchmarking a specific, complex task or running general model evaluations? The right tool should align with your workflow, provide transparent cost and performance data, and fit your team's technical requirements.