Fallom vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
Fallom delivers real-time observability for AI agents, ensuring precise tracking, debugging, and cost management.
Last updated: February 28, 2026
OpenMark AI benchmarks over 100 LLMs on your specific task to find the best model for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
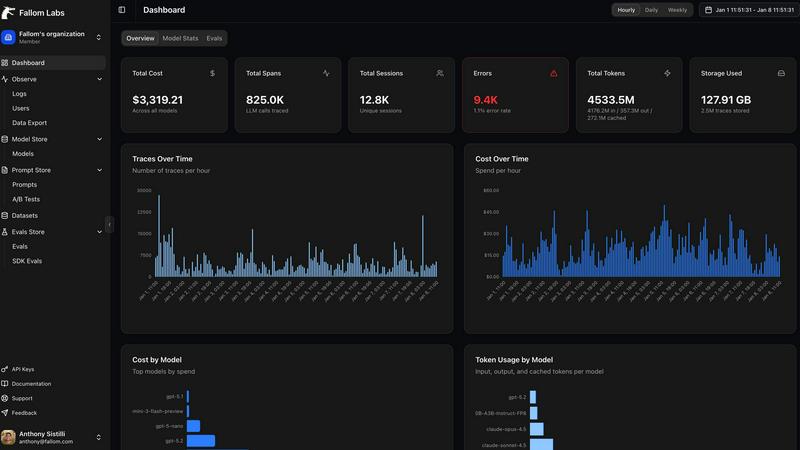
Fallom
OpenMark AI

Feature Comparison
Fallom
Comprehensive LLM Call Tracing
Fallom offers real-time observability for AI agents by enabling teams to track and analyze every LLM call. This feature allows users to debug confidently and understand the timing and costs associated with each call, enhancing overall operational efficiency.
Cost Attribution and Transparency
With Fallom, organizations can effectively track their spending across different models, users, and teams. This feature delivers full cost transparency, making budgeting and chargeback processes seamless and accurate.
Enterprise-Grade Compliance
Fallom is equipped with compliance-ready capabilities that provide complete audit trails to support regulatory requirements. Features include input/output logging, model versioning, and user consent tracking, ensuring that organizations meet standards such as GDPR and the EU AI Act.
Real-time Monitoring and Session Tracking
The platform enables live monitoring of LLM usage, allowing teams to spot anomalies before they escalate into serious incidents. Additionally, session tracking groups traces by user or customer, providing complete context for performance analysis.
OpenMark AI
Plain Language Task Description
You don't need to be a prompt engineering expert to start benchmarking. OpenMark AI allows you to describe the task you want to test in simple, natural language. The platform then configures the benchmark based on your description, making advanced LLM evaluation accessible to developers, product managers, and teams without deep technical expertise in model fine-tuning or complex setup procedures.
Multi-Model Comparison in One Session
Instead of manually testing models one by one across different platforms, OpenMark AI lets you run your identical prompt against dozens of models simultaneously. This side-by-side testing environment provides an immediate, apples-to-apples comparison, saving hours of manual work and providing clear, actionable insights into which model performs best for your specific use case.
Real Cost & Performance Metrics
The platform goes beyond simple accuracy scores. It executes real API calls to each model and reports back the actual cost per request, latency, and a scored quality metric based on your task. This gives you a complete picture of the trade-offs between speed, expense, and effectiveness, allowing for true cost-efficiency calculations before you commit to an API.
Stability and Variance Analysis
A single, lucky output from a model is misleading. OpenMark AI runs your task multiple times for each model to measure consistency. The results show variance across these repeat runs, highlighting which models produce stable, reliable outputs and which ones are unpredictable. This is crucial for deploying production features that users can depend on.
Use Cases
Fallom
Optimizing AI Workflows
Organizations can utilize Fallom to optimize their AI workflows by analyzing LLM call data, identifying bottlenecks, and improving response times. This leads to enhanced efficiency in operations involving AI agents.
Ensuring Compliance in AI Deployments
Fallom's robust compliance features make it ideal for organizations operating in regulated industries. Businesses can maintain compliance with data protection regulations while ensuring that their AI systems are transparent and accountable.
Cost Management in AI Operations
Companies can leverage Fallom to gain insights into their LLM usage costs. By tracking expenses on a per-model and per-user basis, organizations can make informed budgeting decisions and manage their AI investments effectively.
Debugging and Performance Enhancement
Fallom's real-time monitoring capabilities allow teams to debug issues quickly and enhance the performance of their AI agents. By identifying latency problems and performance regressions, organizations can ensure a smoother user experience.
OpenMark AI
Pre-Deployment Model Selection
Before integrating an LLM into a new chatbot, content generation feature, or data processing pipeline, teams can use OpenMark AI to validate which model from the vast available catalog best fits their workflow. This ensures the chosen model aligns with required quality, cost constraints, and performance benchmarks, reducing the risk of post-launch failures or budget overruns.
Cost Optimization for Existing Features
For teams already using an LLM API, OpenMark AI serves as a tool for periodic cost-performance reviews. By benchmarking their current task against newer or alternative models, they can identify if a different provider offers comparable quality at a lower cost or better performance for the same budget, leading to significant long-term savings.
Evaluating Model Consistency for Critical Tasks
When building applications where output reliability is non-negotiable—such as legal document analysis, medical information extraction, or financial summarization—testing for consistency is key. OpenMark AI's variance analysis helps teams disqualify models with high output fluctuation and select those that deliver dependable results every time.
Prototyping and Research for AI Products
Researchers and product innovators exploring new AI capabilities can use OpenMark AI to rapidly prototype ideas. By quickly testing how different models handle a novel task like complex agent routing or multimodal analysis, they can gather data on feasibility and performance without investing in extensive infrastructure or API integrations upfront.
Overview
About Fallom
Fallom is an innovative AI-native observability platform developed specifically for large language model (LLM) and agent workloads. It empowers organizations by providing unprecedented visibility into LLM operations, allowing users to track every LLM call in production. This visibility is achieved through comprehensive end-to-end tracing, which captures essential data points, including prompts, outputs, tool calls, tokens, latency, and per-call costs. The platform is designed for businesses that leverage AI agents, enabling them to effectively monitor and optimize their LLM usage. Fallom's deep insights into user and session-level contexts help teams understand performance metrics and usage patterns. Additionally, it meets enterprise compliance needs with features such as robust logging, model versioning, and consent tracking. With a single OpenTelemetry-native SDK, teams can instrument their applications in just minutes, facilitating live monitoring, rapid debugging, and effective cost attribution across various models, users, and teams.
About OpenMark AI
Choosing the right large language model (LLM) for your AI feature is a high-stakes gamble. Relying on marketing benchmarks or testing one model at a time leaves you guessing about real-world performance, true cost, and output consistency. This uncertainty leads to shipping features that are either too expensive, unreliable, or underperform. OpenMark AI solves this critical pre-deployment challenge. It is a hosted web application designed for developers and product teams to perform task-level LLM benchmarking. You simply describe your specific task in plain language—be it data extraction, translation, or agent routing—and run the same prompts against a vast catalog of over 100 models in a single session. The platform provides side-by-side comparisons using real API calls, not cached data, measuring scored quality, cost per request, latency, and critically, stability across repeat runs to show variance. This means you see which model consistently delivers quality for your unique need at a sustainable cost, eliminating guesswork. With a hosted credit system, you bypass the hassle of configuring multiple API keys, making professional-grade benchmarking accessible without setup. OpenMark AI is built for those who care about cost efficiency (quality relative to price) and consistency, ensuring you deploy with confidence.
Frequently Asked Questions
Fallom FAQ
What industries can benefit from using Fallom?
Fallom is tailored for organizations that rely on AI agents across various industries, including finance, healthcare, retail, and technology, enabling them to optimize their AI operations and ensure compliance.
How quickly can I integrate Fallom into my existing systems?
With Fallom's OpenTelemetry-native SDK, teams can set up and instrument their applications in under five minutes, allowing for rapid integration and immediate start of live monitoring.
What compliance standards does Fallom support?
Fallom is designed to meet various compliance standards, including GDPR, the EU AI Act, and SOC 2, providing organizations with the necessary tools to maintain regulatory compliance in their AI operations.
Can Fallom help with debugging AI models?
Yes, Fallom provides features that allow teams to debug their AI models efficiently. With real-time monitoring and session tracking, users can quickly identify latency issues and performance regressions, leading to improved model performance.
OpenMark AI FAQ
How does OpenMark AI differ from standard model leaderboards?
Standard leaderboards often use generic, one-size-fits-all benchmarks (like MMLU or HellaSwag) that may not reflect your specific task. They also typically show "best-case" or cached results. OpenMark AI requires you to describe your actual task, runs fresh API calls against models in real-time, and measures metrics critical for deployment: your task's quality score, actual API cost, latency, and consistency across multiple runs.
Do I need my own API keys to use OpenMark AI?
No, one of the core conveniences of OpenMark AI is that it operates on a hosted credit system. You purchase credits through OpenMark and the platform manages the API calls to providers like OpenAI, Anthropic, and Google on your behalf. This eliminates the need to sign up for, configure, and manage multiple API keys just to run a comparison.
What kind of tasks can I benchmark with OpenMark AI?
You can benchmark virtually any task you would use an LLM for. The platform is designed for task-level evaluation, including but not limited to text classification, translation, data extraction from documents, question answering, content generation, code explanation, sentiment analysis, and testing components of Retrieval-Augmented Generation (RAG) or agentic workflows.
How does OpenMark AI measure the "quality" of a model's output?
Quality scoring is based on the specific task you define. The platform uses automated evaluation methods tailored to your benchmark's goal. This could involve checking for correctness against a defined answer, using a more powerful LLM as a judge to grade responses, or employing other metrics like semantic similarity. The method is configured to align with your success criteria.
Alternatives
Fallom Alternatives
Fallom is an AI-native observability platform that specializes in providing real-time tracking and insights for large language model (LLM) and agent workloads. By enabling organizations to monitor every aspect of their LLM interactions, Fallom ensures precise debugging, cost management, and compliance with regulatory standards. Given the rapid evolution of AI technologies, users often seek alternatives to Fallom for various reasons, including pricing structures, specific feature sets, or integration capabilities that better fit their unique platform needs. When searching for an alternative to Fallom, it is crucial to consider the platform's observability capabilities, ease of integration with existing systems, and the breadth of analytics provided. Additionally, organizations should evaluate how well potential alternatives can support compliance requirements and facilitate cost tracking, ensuring that they can maintain operational efficiency while managing their AI expenditures effectively.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It helps teams compare cost, speed, quality, and stability across 100+ LLMs using real API calls, all from a single browser-based interface without needing individual provider keys. Users often explore alternatives for various reasons, such as needing a different pricing model, requiring deeper technical integrations like a dedicated API or SDK, or seeking tools focused on different stages of the AI lifecycle, like ongoing monitoring rather than pre-deployment validation. When evaluating other options, consider your core need: do you require hosted simplicity or self-hosted control? Are you benchmarking a specific, complex task or running general model evaluations? The right tool should align with your workflow, provide transparent cost and performance data, and fit your team's technical requirements.