OpenMark AI vs qtrl.ai
Side-by-side comparison to help you choose the right tool.
OpenMark AI benchmarks over 100 LLMs on your specific task to find the best model for cost, speed, and quality.
Last updated: March 26, 2026
qtrl.ai
qtrl.ai scales QA testing with AI agents while ensuring full team control and governance.
Last updated: March 4, 2026
Visual Comparison
OpenMark AI

qtrl.ai
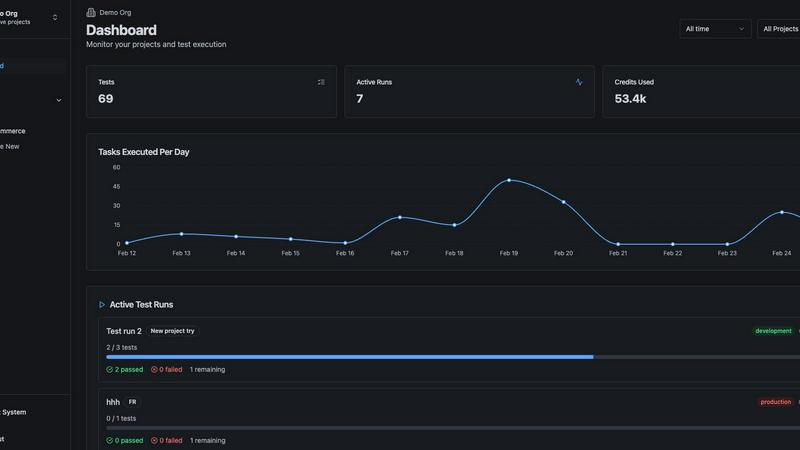
Feature Comparison
OpenMark AI
Plain Language Task Description
You don't need to be a prompt engineering expert to start benchmarking. OpenMark AI allows you to describe the task you want to test in simple, natural language. The platform then configures the benchmark based on your description, making advanced LLM evaluation accessible to developers, product managers, and teams without deep technical expertise in model fine-tuning or complex setup procedures.
Multi-Model Comparison in One Session
Instead of manually testing models one by one across different platforms, OpenMark AI lets you run your identical prompt against dozens of models simultaneously. This side-by-side testing environment provides an immediate, apples-to-apples comparison, saving hours of manual work and providing clear, actionable insights into which model performs best for your specific use case.
Real Cost & Performance Metrics
The platform goes beyond simple accuracy scores. It executes real API calls to each model and reports back the actual cost per request, latency, and a scored quality metric based on your task. This gives you a complete picture of the trade-offs between speed, expense, and effectiveness, allowing for true cost-efficiency calculations before you commit to an API.
Stability and Variance Analysis
A single, lucky output from a model is misleading. OpenMark AI runs your task multiple times for each model to measure consistency. The results show variance across these repeat runs, highlighting which models produce stable, reliable outputs and which ones are unpredictable. This is crucial for deploying production features that users can depend on.
qtrl.ai
Enterprise-Grade Test Management
qtrl provides a centralized, structured foundation for all QA activities. Teams can create and organize test cases, plan comprehensive test runs, and establish full traceability from requirements to test coverage. Real-time dashboards offer clear visibility into quality metrics, showing exactly what has been tested, pass/fail statuses, and potential risk areas. This manual and automated workflow management is built with compliance and auditability as first principles, ensuring teams never lose oversight.
Progressive AI & Autonomous QA Agents
Instead of a risky "black-box" AI takeover, qtrl introduces intelligent automation progressively. Teams begin by writing high-level test instructions in plain English, which qtrl's agents execute precisely. As trust builds, teams can leverage AI to generate full test scripts from descriptions and maintain them as the application evolves. These autonomous agents operate within defined rules, executing tests on-demand or continuously across multiple environments at scale, using real browsers—not simulations.
Adaptive Memory & Intelligent Suggestions
The platform builds a living, evolving knowledge base of your application through every interaction—exploration, test execution, and issue discovery. This Adaptive Memory powers context-aware test generation that becomes more effective over time. Furthermore, qtrl proactively analyzes coverage gaps and suggests new tests to fill them, transforming the QA process from reactive maintenance to intelligent, continuous quality improvement.
Governance by Design & Multi-Environment Execution
qtrl is built for enterprise trust, with transparency and control embedded in its architecture. It offers permissioned autonomy levels, full visibility into agent actions, and enterprise-ready security. For execution, it supports running tests across any environment (dev, staging, production) with per-environment variables and encrypted secrets. Critically, these secrets are never exposed to the AI agent, ensuring security is never compromised for the sake of automation.
Use Cases
OpenMark AI
Pre-Deployment Model Selection
Before integrating an LLM into a new chatbot, content generation feature, or data processing pipeline, teams can use OpenMark AI to validate which model from the vast available catalog best fits their workflow. This ensures the chosen model aligns with required quality, cost constraints, and performance benchmarks, reducing the risk of post-launch failures or budget overruns.
Cost Optimization for Existing Features
For teams already using an LLM API, OpenMark AI serves as a tool for periodic cost-performance reviews. By benchmarking their current task against newer or alternative models, they can identify if a different provider offers comparable quality at a lower cost or better performance for the same budget, leading to significant long-term savings.
Evaluating Model Consistency for Critical Tasks
When building applications where output reliability is non-negotiable—such as legal document analysis, medical information extraction, or financial summarization—testing for consistency is key. OpenMark AI's variance analysis helps teams disqualify models with high output fluctuation and select those that deliver dependable results every time.
Prototyping and Research for AI Products
Researchers and product innovators exploring new AI capabilities can use OpenMark AI to rapidly prototype ideas. By quickly testing how different models handle a novel task like complex agent routing or multimodal analysis, they can gather data on feasibility and performance without investing in extensive infrastructure or API integrations upfront.
qtrl.ai
Scaling Beyond Manual Testing
QA teams overwhelmed by repetitive manual test cycles can use qtrl to systematically scale their efforts. They start by structuring their existing manual cases in the test management hub for better visibility. Then, they progressively automate the most tedious, high-value UI workflows using plain English instructions, freeing up human testers for more complex exploratory work and significantly accelerating release cycles without a steep learning curve.
Modernizing Legacy QA Workflows
Companies relying on outdated, siloed, or script-heavy automation frameworks can modernize without a disruptive rip-and-replace project. qtrl integrates with existing tools and CI/CD pipelines, allowing teams to bring their current processes into a centralized platform. They can then incrementally augment or replace brittle scripts with AI-generated tests that are easier to create and maintain, building a more resilient and efficient QA ecosystem over time.
Governing Enterprise AI Testing
For large organizations in regulated industries that require strict compliance, audit trails, and governance, qtrl provides a safe path to AI adoption. Its permissioned autonomy, full audit logs of all agent activities, and "no black-box" policy ensure that AI augments the QA process without introducing unpredictable risk. Engineering leads can grant automation capabilities while retaining ultimate approval and control over what tests run and what changes are made.
Empowering Product-Led Engineering Teams
Product-focused engineering teams that need to move fast but maintain high quality can embed qtrl into their development lifecycle. Developers can write high-level test instructions for new features, and qtrl handles the execution, providing immediate feedback. The platform's coverage analysis and test suggestions help ensure no regression is introduced, enabling faster, more confident deployments aligned with a product-led growth strategy.
Overview
About OpenMark AI
Choosing the right large language model (LLM) for your AI feature is a high-stakes gamble. Relying on marketing benchmarks or testing one model at a time leaves you guessing about real-world performance, true cost, and output consistency. This uncertainty leads to shipping features that are either too expensive, unreliable, or underperform. OpenMark AI solves this critical pre-deployment challenge. It is a hosted web application designed for developers and product teams to perform task-level LLM benchmarking. You simply describe your specific task in plain language—be it data extraction, translation, or agent routing—and run the same prompts against a vast catalog of over 100 models in a single session. The platform provides side-by-side comparisons using real API calls, not cached data, measuring scored quality, cost per request, latency, and critically, stability across repeat runs to show variance. This means you see which model consistently delivers quality for your unique need at a sustainable cost, eliminating guesswork. With a hosted credit system, you bypass the hassle of configuring multiple API keys, making professional-grade benchmarking accessible without setup. OpenMark AI is built for those who care about cost efficiency (quality relative to price) and consistency, ensuring you deploy with confidence.
About qtrl.ai
qtrl.ai is a modern, progressive QA platform designed to solve the critical scaling challenges faced by software teams today. It bridges the frustrating gap between the slow, unscalable nature of manual testing and the brittle, expensive complexity of traditional test automation. qtrl uniquely combines robust, enterprise-grade test management with powerful, trustworthy AI automation, all within a single, governed platform. Its core value proposition is enabling teams to scale their quality assurance efforts without ever sacrificing control, visibility, or governance. Teams start with a centralized hub for organizing test cases, planning runs, tracing requirements, and tracking real-time quality metrics. From this foundation of clarity and control, they can progressively introduce intelligent automation. qtrl's autonomous agents can generate and maintain UI tests from plain English, executing them at scale across real browsers and environments. This makes it the ideal solution for product-led engineering teams, QA groups moving beyond manual processes, companies modernizing legacy workflows, and any enterprise that requires strict compliance, full audit trails, and a trusted path to faster, more intelligent quality assurance.
Frequently Asked Questions
OpenMark AI FAQ
How does OpenMark AI differ from standard model leaderboards?
Standard leaderboards often use generic, one-size-fits-all benchmarks (like MMLU or HellaSwag) that may not reflect your specific task. They also typically show "best-case" or cached results. OpenMark AI requires you to describe your actual task, runs fresh API calls against models in real-time, and measures metrics critical for deployment: your task's quality score, actual API cost, latency, and consistency across multiple runs.
Do I need my own API keys to use OpenMark AI?
No, one of the core conveniences of OpenMark AI is that it operates on a hosted credit system. You purchase credits through OpenMark and the platform manages the API calls to providers like OpenAI, Anthropic, and Google on your behalf. This eliminates the need to sign up for, configure, and manage multiple API keys just to run a comparison.
What kind of tasks can I benchmark with OpenMark AI?
You can benchmark virtually any task you would use an LLM for. The platform is designed for task-level evaluation, including but not limited to text classification, translation, data extraction from documents, question answering, content generation, code explanation, sentiment analysis, and testing components of Retrieval-Augmented Generation (RAG) or agentic workflows.
How does OpenMark AI measure the "quality" of a model's output?
Quality scoring is based on the specific task you define. The platform uses automated evaluation methods tailored to your benchmark's goal. This could involve checking for correctness against a defined answer, using a more powerful LLM as a judge to grade responses, or employing other metrics like semantic similarity. The method is configured to align with your success criteria.
qtrl.ai FAQ
How does qtrl.ai ensure control and governance over AI actions?
qtrl is built with governance as a core design principle. It does not operate as a black box. Teams set permission levels for autonomy, and all AI-generated tests or actions are fully reviewable and require human approval before implementation. The platform provides complete visibility into every action an autonomous agent takes, maintains full audit trails for compliance, and allows teams to define the exact rules and boundaries within which the AI operates.
Can qtrl.ai integrate with our existing development tools and CI/CD pipeline?
Yes, qtrl is designed to fit into real-world engineering workflows. It offers integrations for requirements management and seamless support for CI/CD pipelines. This allows teams to trigger automated test suites as part of their build and deployment processes, enabling continuous quality feedback loops. qtrl works alongside your existing toolchain to enhance it, not replace it forcibly.
Is my application data secure, especially when using AI agents?
Absolutely. qtrl employs enterprise-grade security measures. A key feature is the secure handling of sensitive data: per-environment variables and encrypted secrets (like login credentials) are managed securely and are never exposed to the AI agents. The agents execute tests without accessing the underlying secret values, ensuring that your most sensitive data remains protected while still enabling automated testing.
What if we are not ready for full AI automation? Can we still use qtrl?
Yes, this is a fundamental strength of qtrl's progressive approach. You can start using it solely as a powerful, structured test management platform to organize manual test cases and plans. You can then introduce automation at your own pace, beginning with simple, human-written instructions for the agent to execute. The AI capabilities are there to leverage when you are ready, allowing you to start simple and scale intelligence over time.
Alternatives
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It helps teams compare cost, speed, quality, and stability across 100+ LLMs using real API calls, all from a single browser-based interface without needing individual provider keys. Users often explore alternatives for various reasons, such as needing a different pricing model, requiring deeper technical integrations like a dedicated API or SDK, or seeking tools focused on different stages of the AI lifecycle, like ongoing monitoring rather than pre-deployment validation. When evaluating other options, consider your core need: do you require hosted simplicity or self-hosted control? Are you benchmarking a specific, complex task or running general model evaluations? The right tool should align with your workflow, provide transparent cost and performance data, and fit your team's technical requirements.
qtrl.ai Alternatives
qtrl.ai is a modern QA platform in the automation and dev tools category. It helps software teams scale testing by combining structured test management with trustworthy AI agents, offering a controlled path to intelligent automation. Users often explore alternatives for various reasons. These can include budget constraints, the need for a different feature set, or specific platform requirements like deeper integration with an existing toolchain. The search for the right fit is a normal part of the software selection process. When evaluating options, consider your team's primary goals. Look for a solution that balances powerful automation with the governance and control your processes demand. The ideal platform should grow with you, providing a clear path from manual testing to scalable, AI-assisted quality assurance without becoming a black box.