Pinecone
About Pinecone
Pinecone is an innovative vector database catering to AI developers and businesses seeking rapid data retrieval. It allows users to perform low-latency vector searches through vast datasets for applications like search and recommendations. Pinecone’s unique serverless design simplifies management while ensuring optimum performance.
Pinecone offers a flexible pricing plan starting with a free tier for new users. As you scale, you can upgrade to higher tiers that provide more features and benefits. The upgrade path is designed to facilitate growth, making it easy to pay as you go while accessing advanced capabilities.
Pinecone's user interface is designed for seamless interaction, featuring an intuitive layout that simplifies navigation across its functionalities. The platform boasts user-friendly elements, ensuring that both developers and businesses can efficiently manage their search requirements and quickly access vital information.
How Pinecone works
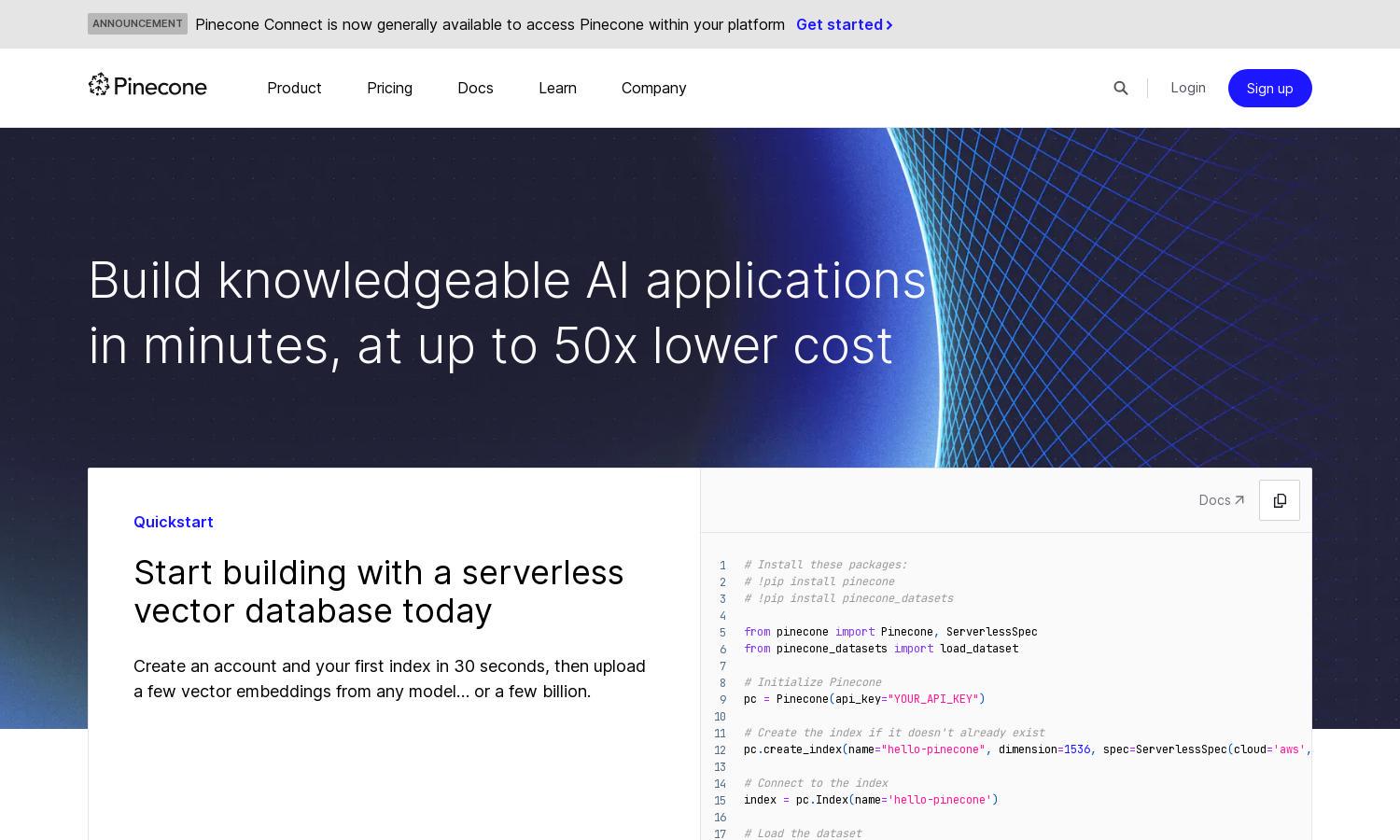
Users interact with Pinecone by creating an account and setting up their first index within seconds. After uploading vector embeddings, they can perform vector searches effortlessly. The platform updates in real-time, enhancing the search experience by delivering relevant and up-to-date results as new data comes in.
Key Features for Pinecone
Real-time Vector Search
Pinecone's real-time vector search stands out as a core functionality, enabling users to efficiently retrieve relevant data from vast datasets. This innovative feature ensures that developers can enhance their AI applications with precise results, making Pinecone a preferred choice for advanced data applications.
Serverless Architecture
Pinecone's serverless architecture allows users to focus on their AI projects without the hassle of managing database infrastructure. This unique aspect provides businesses with the agility to scale effortlessly, as they can pay only for what they need, promoting efficient resource allocation and cost savings.
Low-latency Performance
Pinecone delivers low-latency performance, ensuring that searches are executed in milliseconds. This key feature significantly enhances user experience, as it empowers developers to build responsive AI applications that leverage rapid data retrieval, ultimately leading to superior application performance and customer satisfaction.
You may also like: