WebPageSnap - Professional Web Scraper API
WebPageSnap is a powerful web scraper API that effortlessly extracts data from any webpage while bypassing anti-bot.
Visit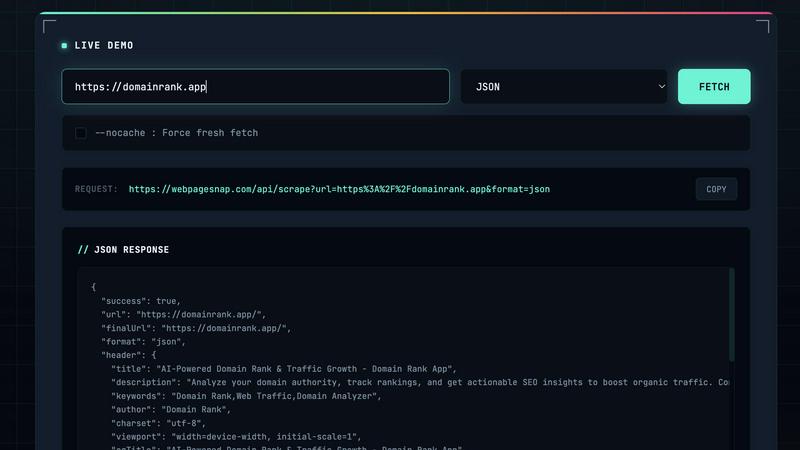
About WebPageSnap - Professional Web Scraper API
WebPageSnap is a powerful and efficient web scraping API specifically designed for enterprises and developers seeking reliable data extraction solutions. This API allows users to programmatically fetch and parse content from any public webpage, effectively overcoming the complexities often associated with web scraping at scale. Given the typical challenges such as managing proxies, circumventing anti-bot measures, and dealing with inconsistent HTML, WebPageSnap simplifies these processes by leveraging Cloudflare's robust global infrastructure. It provides high-performance services that yield sub-50ms response times for cached requests and boasts a remarkable 95% cache hit rate. The main value proposition of WebPageSnap lies in its ability to deliver structured JSON data or raw HTML with minimal latency, making it an ideal choice for developers, data scientists, and businesses that require consistent and reliable web data without the need to maintain intricate scraping frameworks. By using WebPageSnap, users can focus on data analysis and application development rather than the technical details of web scraping.
Features of WebPageSnap - Professional Web Scraper API
Smart Cache
WebPageSnap includes an intelligent caching mechanism with a key-value storage system and a seven-day time-to-live (TTL). This feature significantly enhances performance by allowing the API to serve requests from cache, ensuring that users experience fast response times and reducing the load on the server.
Global Edge
With deployment across more than 200 edge nodes worldwide, WebPageSnap guarantees that users receive the quickest possible response times by connecting to the nearest edge location. This global distribution minimizes latency and ensures optimal performance regardless of the user's location.
Multi Format
WebPageSnap supports multiple output formats, allowing users to receive scraped data in either structured JSON or raw HTML. This flexibility ensures that developers can easily integrate the data into their existing workflows, adapting to various use cases and requirements.
Smart Redirect
The API is equipped with a smart redirect feature that automatically follows JavaScript redirects, ensuring that users receive the content from the final destination. This capability is crucial for accessing content on modern web pages that rely heavily on JavaScript for navigation and display.
Use Cases of WebPageSnap - Professional Web Scraper API
Market Research
Businesses can utilize WebPageSnap to gather competitor data and market insights from various websites. By extracting product information, pricing strategies, and customer reviews, organizations can make informed decisions and enhance their competitive edge.
Content Aggregation
WebPageSnap is ideal for content aggregation platforms that need to compile information from multiple sources. Whether it's news articles, blog posts, or product listings, the API can efficiently scrape and structure this data for seamless integration into a unified platform.
SEO Analysis
SEO professionals can leverage WebPageSnap to analyze website content and metadata. By extracting key elements such as titles, descriptions, and keywords, users can gain valuable insights into website performance and optimize their strategies for better search engine rankings.
Data Migration
When transitioning from one platform to another, WebPageSnap can facilitate data migration by scraping existing content from legacy systems or websites. This ensures that businesses retain valuable information without the need for manual data entry, saving time and resources.
Frequently Asked Questions
What is a web scraper API?
A web scraper API is a service that enables users to programmatically extract data from websites. WebPageSnap provides a robust API that returns data in structured JSON or HTML formats, simplifying the integration of web scraping into applications.
How does this web scraper API handle JavaScript pages?
WebPageSnap automatically detects and follows JavaScript redirects, simulating real browser behavior to ensure users receive the final page content. This feature is essential for scraping modern websites that rely on JavaScript for navigation.
Is the web scraper API free to use?
Yes, WebPageSnap offers a generous free tier that allows users to make up to 100,000 requests per day. This accessibility makes it an attractive option for developers and businesses looking to experiment with web scraping.
How do I get started with WebPageSnap?
To begin using WebPageSnap, simply sign up for an account on their website. Once registered, you can access the API documentation, which provides detailed instructions for making requests and utilizing the various features available.
Explore more in this category:
Similar to WebPageSnap - Professional Web Scraper API
Social Fetch
Social media scraper API: scrape profiles, posts, comments, and transcripts from TikTok, Instagram, YouTube, X, and 20+ platforms via REST.
Linkfinder AI
LinkFinder AI enriches your leads with accurate company details from multiple sources in minutes, boosting your sales.
BlitzAPI
BlitzAPI empowers your growth team with instant access to clean B2B data through scalable, powerful APIs for GTM.
LLMWise
LLMWise offers a single API to access multiple AI models, optimizing your prompts while you pay only for what you use.
Anti Tempmail
AntiTemp empowers teams to verify emails intelligently, ensuring growth while mitigating abuse with real-time insights.

My Deepseek API
Unlock powerful AI capabilities with My Deepseek API—affordable, scalable, and designed for all your needs.
CCAPI
CCAPI is your all-in-one AI API gateway, offering seamless access to diverse AI models for text, image, audio, and.
Renderly
Renderly automates video production at scale, generating thousands of personalized videos quickly through a powerful.